
コンペ概要
下記Signateのコンペの説明より転載しています。
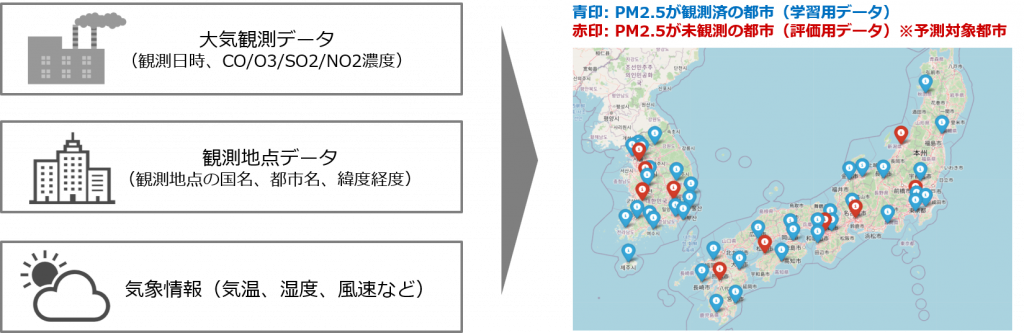
世界各都市の大気観測データ(観測日時、位置情報、PM2.5以外の大気物質濃度)、気象情報(天気、湿度、風速等)、及び必要に応じて外部データを用いて、特定の日時・都市における「PM2.5濃度」を予測していただきます。
・学習用データと評価用データにはそれぞれ別の都市のデータが含まれており、評価用データのPM2.5濃度が「未観測」の都市が予測対象となります。
結果
結果は残念ながら62位でした。他の方々の結果と比較すると、ずっと過学習気味でモデルを作成していたようです。アンサンブルなどもトライしたのですが、スコアが出ず、LightGBMにTargetEncordingで説明変数を増やしただけというモデルになりました。PM2.5がどのように拡散していくか、どのように発生するかは大気の動きと関係していて、予測がしにくく、空間的には観測点がまちまちで予測しにくいという難しさを持った問題だったと思います。
提出したモデルの説明
考え方
1日前のpm2.5が時間とともにどこに行くかは地形情報や地上付近の風、上空の風、拡散係数やpm2.5自体の発生など、影響されるものが多すぎるので、基本的に同じ日のデータを使って領域方向の推論で予測をすることを考えました。
CityのDrop
目視で明らかにTestデータから遠そうなCityの情報は削っています。
’Novosibirsk’,’Darwin’, ‘Perth’,’Ürümqi’, ‘Naha’, ‘Calama’, ‘Sapporo’, ‘Hegang’, ‘Bandar Abbas’, ‘Yazd’を削りました。
クラスタリング
k-meansで40領域に分割しています。pm2.5の推論に対するlgbmの緯度の重要度が低かったため、微妙に緯度方向の重みを減らしてクラスタリングしてみましたが、あまり効果ありませんでした。
Target Encoding 1
各都市の周囲に正方領域を切り取り、score = (co_mid * 0.8 + no2_mid* 0.2)の値が一番近い都市を探します。その都市のco_mid、no2_midとpm25_midの値、緯度、経度情報をneighbor情報として追加しています。データが存在しない場合は領域を拡大して探しています。
Target Encoding 2
クラスタリングで求めた40領域を年と月ごと(3年x 12か月で36とおり)にpm25_midの平均値を求めてデータフレームに追加してます。TrainDataのTarget Encordig時はkfoldで4分割して、自分を含むデータが入らないようにしています。Test Dataには単純にTrainDataから求められる平均値を入れています。
Target Encordingした値は平均・最大・最小・標準偏差を求めて特徴量として追加してます。
データ分割
kfold, 分割数6です。分割数5よりもPublicの結果が良かったので、6にしてみました。
model
LightBGMです。numleaves = 70です。
optuna
手持ちのノートパソコンでは計算時間がかかりすぎるため、今回使用していません。
コード
GitHubのこちらのページにおいてあります。
https://github.com/niseng-biz/signate_estimate_pm25_sony
以上、何かの参考になれば幸いです。記事をご覧いただき、ありがとうございました。


